Most of us are well aware of the phrase "correlation is not causation" but only few of us are capable of seeing past our biases. In order to spot the biases, the bias detection engine in our brains will have to be trained to spot them. We must develop the ability to discern the difference between causation and correlation. It is not easy, the dynamics of the system do not allow for such a provision without going through the hard route of training oneself to peruse every piece of information we receive. And luckily for us, mathematicians and statisticians have already created a framework to work with, the study of causality through analysis of information, also known as Causal Inference. This is my attempt at compiling a guide that you can use to understand the science of causality.
Causal Inference is a sub-field in Information Theory and Probability Theory. But one doesn't have to be a statistician or a mathematician to go about understanding the basics of causality theory. Anyone with an interest in knowing about causation is perfectly capable of learning it. Learning the applications of causality theory can be real helpful for all us to navigate our lives better and also help us make better decisions throughout our lives. Before we start, this essay is more like a transcription of an online course hosted in coursera on causal inference by U Penn. It is based on my notes on the aforementioned course. So, please feel free to checkout the course to get a better understanding of the topic.
Okay, now that we are done with the introduction and housekeeping, let us dive right in.
Confusion over causality
The lack of clarity in identifying what is causality is our first and major roadblock in overcoming the biases. We as human beings have a tendency to confuse unrelated variables to causality. And in some instances, we may remain unaware of the mistake until we are made aware of it later by some new research. It is also possible that we may remain unaware of it all our life, attributing our success/failure to some completely irrelevant variable. The confusion can arise due to many things – spurious correlations, anecdotes, science reporting, reverse causality etc.
Spurious Correlation
Causally unrelated variables might happen to be highly correlated with each other over some period of time.
For eg. You could have a graph showing relation between wheat production in Asia and Divorce rate in Europe from 2004 to 2009, but we can be certain to some extent in this case that no matter how much closely related these lines are, there is very little chance for wheat production to affect the divorce rate in Europe. Since there is always some remote chance for two completely unrelated quantities to be correlated, this might be confusing if we don't understand causality.
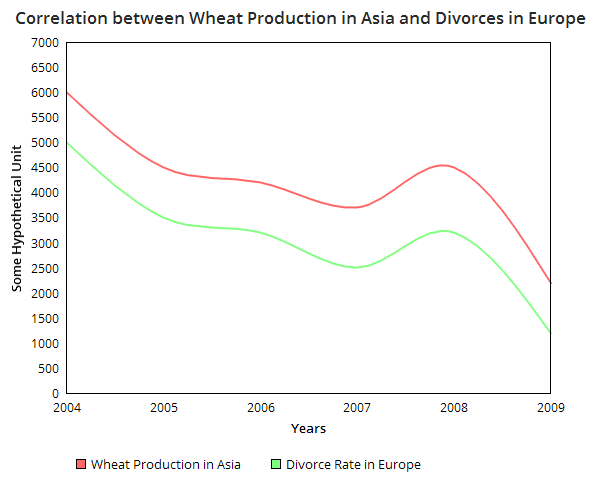 Fig1. This is made up data
Fig1. This is made up data
Anecdotes
People have beliefs about causal effects in their own lives.
For eg. Suzuka Okinawa lived to be 115 years old. She said the secret to her longevity was eating one bitter-gourd a day. And because that is one visible difference that separates her from others who do not live that long, she believes that the bitter-gourd is the cause of her longevity. But we do not know if it is causal at all and we can't know for sure unless we can eliminate her other dietary details, lifestyle details, environmental details etc. Hypothetically speaking, it is also possible that if she had not eaten one bitter-gourd a day, she could have lived longer for all we know.
Science Reporting
Headlines often do not use the forms of the word cause, but do get interpreted causally.
For eg. "Diet high in red meat linked to inflammatory bowel condition, study suggests"
News headlines tend to use loaded words like "linked" that can mean many things. In our case, it could be that red meats cause the condition, it could also mean that it might just deteriorates the condition, or for that matter it could be possible that helps to get better. And when conjoined with the word study suggests, this can lead to confusions. One would need the details of the research to know better.
If you know about causality and know about the topic in question, you might ignore it attributing to wrong correlation but if you are really excited about it, you might share it with others without realizing the effects of it on others. Hence it is really important to know how the experiment is designed, how the information was collated, and other details involved in the research before making an well-informed decision.
Reverse Causality
Even if there is a causal relationship, sometimes the direction can be unclear. And here what we are talking about is that the relationship between two variable could be bi-directional.
For eg. urban green space and exercise.
- Are physically active people more likely to prioritize living near green space?
- Or, Does green space in urban environment cause people to exercise more?
The causal arrow in this case could go in either directions. In such cases, we need temporal data to solve the chicken and egg problem.
How to one clear up the confusion?
The field of causal inference or causal modeling attempts to do so by proposing:
- Formal definition of causal effects
- assumptions necessary to identify causal effects from data
- rules about what variables need to be controlled for
- sensitivity analyses to determine the impact of violations of assumptions on conclusion